
Wie misst man Textqualität im digitalen Zeitalter? Das war die Leitfrage, die wir im Projekt MIT.Qualität bearbeitet haben. Wir taten dies in zwei Arbeitsbereichen, die jeweils unterschiedliche Aspekte des „wie“ in unserer Leitfrage behandeln:
Im Arbeitsbereich „Modellbildung und Kategorienfindung“ entwickelten wir ein Modell, das „traditionelle“ Ansätze zur Textbewertung mit Blick auf die Besonderheiten digitaler Kommunikation erweitert. „Wie“ ist also im Sinne von „mit welchen Maßstäben, mit welchen Kategorien misst man Textqualität?“ zu verstehen.
Im Arbeitsbereich „Methodenexploration“ haben wir Fallstudien zur „Messbarkeit“ von Textqualität durchgeführt.Das „Wie“ wird hierbei bearbeitet als „mit welchen Methoden, auf welcher Datengrundlage misst man Textqualität?“.
In unserem Blog stellen wir in sechs Blogbeiträgen die Ergebnisse unseres Projekts vor. Dieser Beitrag fokussiert auf unseren Ansatz zur Modellbildung im ersten Arbeitsbereich.
Die VolkswagenStiftung hat uns durch ihre Förderung im Programm „Originalitätsverdacht? Neue Optionen für die Geistes- und Kulturwissenschaften“ die Möglichkeit eröffnet, unsere Ideen umzusetzen. Hierfür möchten wir uns an dieser Stelle sehr herzlich bedanken.
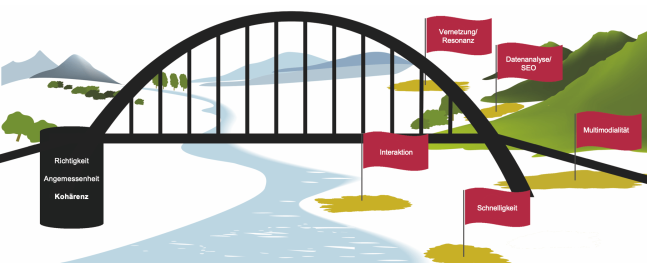
Modellbildung als Brückenschlag zwischen Tradition und Innovation
Unser Leitgedanke bei der Modellbildung war es, traditionelle und neue Kategorien zur Qualitätsbewertung miteinander zu verbinden. Um die Arbeiten in Bereich „Modellbildung und Kategorienfindung“ besser einordnen und erklären zu können, haben wir diesen Leitgedanken mit dem oben angefügten Bild des Brückenbaus visualisiert.
Die linke Brückenseite steht für die traditionellen Ansätze zur Textbewertung, auf die wir uns gestützt haben. An der Baustelle auf dieser linken Seite ergänzen und modernisieren wir diese Ansätze. Modernisierung ist notwendig, um die Veränderungen im Gebrauch der Schriftsprache, wie sie z.B. in Chats, WhatsApp oder in den Kommentarbereich von Social-Media-Plattformen sichtbar werden, adäquat einordnen und bewerten zu können. Ergänzungen sind notwendig, um dabei neue digitale Zeichentypen – Emojis, GIFs etc. – und neue Vernetzungsmittel wie Links, Hashtags und Adressierungen erfassen zu können. Dieser Blogbeitrag konzentriert sich auf diese Erweiterungen und Modernisierungsarbeiten am linken Brückenpfeiler.
Die rechte Brückenseite steht für neue Kategorien, die speziell für die Qualitätsbewertung von Social-Media-Texten relevant sind. Es ist nicht trivial, diese Kategorien zu finden und zu systematisieren, denn vieles ist im Fluss, verschiedene Social-Media-Plattformen stellen unterschiedliche Anforderungen, die sich zudem laufend verändern. Wenn man im Bild unseres Brückenbaus bleibt, ging es zunächst also darum, an einem noch weitgehend unerschlossenen und schnell veränderlichen Flussufer festen Grund zu finden, d.h. zentrale Kategorien zu identifizieren, an denen ein Brückenschlag ansetzen kann. Das Vorgehen und die Ergebnisse sind im Blogbeitrag von Maja Linthe beschrieben.
Insgesamt entstand ein Analysemodell für digitale Texte, das an traditionelle Ansätze zur Textbewertung anschließt, aber auch neue Kategorien enthält, die für die Bewertung von Textqualität in sozialen Medien und der internetbasierten Kommunikation relevant und wichtig sind. Eine ausführliche Darstellung des Modells wird in einem gemeinsamen Sammelband zur den Projektergebnissen in der Zeitschrift „Deutsche Sprache“ erscheinen.
Auf den Schultern von Riesen: traditionelle Ansätze zur Bewertung von Textqualität als Basis für die Modellbildung
Um unser Modell anschlussfähig an bewährte Kategorien und etablierte Ansätze zu machen, haben wir uns auf die folgenden Ansätze gestützt:
- Grundlegend ist das Zürcher Textanalyseraster, dessen texttheoretische Fundierung u.a. in Nussbaumer 1991 beschrieben ist. Dieser Ansatz wurde im prädigitalen Zeitalter bereits erfolgreich für eine große Studie zur Bewertung von Schülertexten und zur Untersuchung von Veränderungen im Schreibgebrauch genutzt.
- Der Ansatz der dynamischen Texttheorie von Gerd Fritz liefert viele wertvolle Ansatzpunkte, insbesondere für die Erweiterung des Kohärenzbegriffs auf interaktionale und multimodale Kohärenz.
- Dem Ansatz von Thomas Bartz (Bartz 2018) haben wir viele Anregungen entnommen, insbesondere die feinere Differenzierung der Bewertungsprädikate für verschiedene Dimensionen der Textqualität.
- Alle drei Ansätze greifen Kategorien und Empfehlungen der antiken Rhetorik auf, die somit auch in unser Modell einfließen. Das gilt u.a. für die Unterscheidung zwischen Richtigkeit (recte dicendi) und Angemessenheit (bene dicendi), die den Aufbau des Zürcher Rasters prägt. Diese Unterscheidung ist auch zentral für die die Bewertung digitaler Texte, weil dort – wie beim literarischen Schreiben oder in der Werbung – das normabweichende Schreiben durchaus angemessen sein kann.
Unser Modell im Überblick
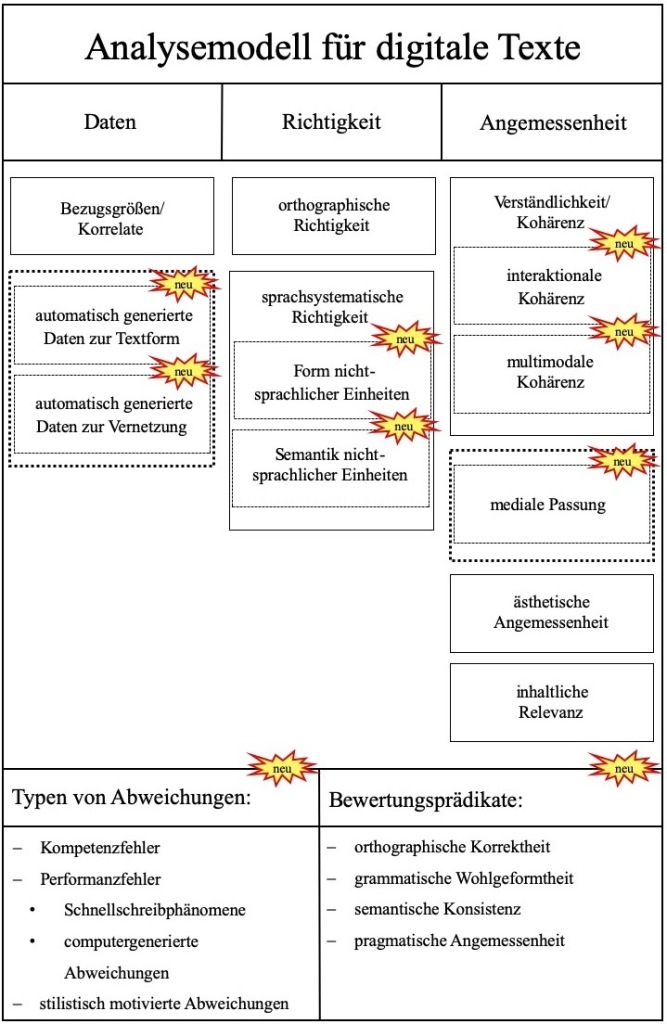
Unser Modell übernimmt aus dem Zürcher Textanalyseraster die Unterscheidung der drei Grundbereiche: Daten (im Zürcher Modell: „Korrelate Bezugsgrößen“), Richtigkeit und Angemessenheit sowie die dazugehörigen Teilbereiche. Es erweitert und modernisiert diesen Ansatz um Teilbereiche, die in unserem Modellüberblick (vgl. Abbildung) als „neu“ gekennzeichnet sind. Ich möchte im Folgenden kurz an Beispielen motivieren, warum wir sie eingeführt haben.
Bereich Daten: Erweiterung für automatisch generierte Daten
Das Zürcher Modell erfasst im Bereich „Korrelate / Bezugsgrößen“ Daten zur Textform, z.B. Zahl der Wortformen, Zahl der Lexeme, Teil- und Ganzssätze etc. Diese dienen als Bezugsgrößen, um den Wortschatz oder die syntaktische Komplexität eines Textes zu charakterisieren.
Bei digitalen Texten lassen sich Daten zur Textform einfach und schnell automatisch erheben. Im Netz finden sich immer mehr Werkzeuge, die Textqualitäten automatisch diagnostizieren. Unsere Fallstudie hat zwar gezeigt, dass deren Ergebnisse beim aktuellen Stand der Kunst nicht immer im Einklang mit den Intuitionen menschlicher Textnutzer stehen (vgl. den Blogbeitrag von Leonie Bröcher). Dennoch halten wir es für zeitgemäß, die neuen, automatischen Instrumente zur Textbewertung ins Modell zu integrieren. Dabei unterscheiden wir zwischen automatisch erzeugten Daten zu Formeigenschaften und automatisch erzeugte Daten zur Vernetzung (Anzahl von ein- und ausgehenden Links, Zahl von Followern, Likes etc.), die in den sozialen Medien auch Aufschluss über Resonanz, Reichweite geben.
Bereich Richtigkeit: Neue Zeichentypen und feinere Bewertungsprädikate
Das Zürcher Textanalyseraster wurde für die Bewertung von Texten in Bildungsinstitutionen entwickelt. Damit ist die Orientierung an der deutschen Standardsprache implizit vorgegeben. Dies ist auch sinnvoll, denn die Befähigung, Texte standardgerecht verfassen zu können, ist weiterhin eine wichtige Voraussetzung für viele Berufsbilder.
Natürlich gibt es auch im Netz viele digitale Texte, die mit Bedacht und Sorgfalt geschrieben und erst nach mehreren Korrekturgängen gepostet werden. In anderen Bereichen des Internets kommt es oft weniger auf die geschliffene Formulierung an. Chats oder Kommentarbereiche auf Social-Media-Plattformen suggerieren ein Szenario des informellen mündlichen Gesprächs, bei dem sprachlich andere Register gezogen werden können als in der schriftlichen Standardsprache. Schnelligkeit ist in der Interaktion ein wichtiger Faktor; die Normorientierung kann weniger wichtig sein als eine rasche Reaktion. Inhaltliche Relevanz, Aktualität und Engagement für das Anliegen der Community werden oft höher bewertet als sprachliche und formale Korrektheit. Viele Angebote des Social Web funktionieren nur, weil die Nutzer partizipieren können, ohne viel Aufwand in die Textgestaltung zu investieren.
Geschrieben wird nicht mehr nur am Schreibtisch, sondern auch unterwegs, oft unter Multitasking-Bedingungen. Dies zieht Aufmerksamkeit ab und begünstigt Flüchtigkeitsfehler. Digitale Schreibassistenzsysteme können diese verhindern, bauen aber oft unbemerkt lexikalische Fehler ein. Zudem hat sich im Internet schon sehr früh ein spielerischer Umgang mit Sprache und Schrift entwickelt, bei dem Normabweichungen bewusst eingesetzt werden. Gemeinsam mit Michael Beißwenger habe ich an Beispielen aus der frühen Chatkommunikation gezeigt, wie die Beteiligten sprachliche und nicht-sprachliche Ressourcen sehr kreativ für Spiel und Spaß einsetzen (Beißwenger / Storrer 2012).
Diese neuen Verhältnisse im Umgang mit Schriftsprache müssen bei einer adäquaten Bewertung sprachlicher Richtigkeit in digitalen Texten berücksichtigt werden. In unserem Modell unterscheiden wir deshalb zwischen verschiedenen Typen von Abweichungen: Abweichungen, die auf mangelnde Sprachkompetenz zurückgehen (Kompetenzfehler) und Abweichungen, die „versehentlich“ entstehen (Performanzfehler). Zu den Performanzfehlern rechnen wir neben den Flüchtigkeitsfehlern, die man auch in Aufsatztexten findet, auch Schnellschreibphänomene, wie sie für das Chatten charakteristisch sind, und computergenerierte Fehler, wie sie z.B. von automatischen Korrekturprogrammen eingefügt werden. Weiterhin bewerten wir typisch netzsprachliche Abweichungen (sog. Netzjargon oder die sog. VONG-Sprache) nicht als Fehler, sondern als stilistisch motivierte Abweichungen, die bewusst eingesetzt werden, z.B. um Gruppenzugehörigkeit zu demonstrieren.
Gerade im sog. „Netzjargon“ entwickeln sich eigene Konventionen zur Verwendung, Bildung und Interpretation nicht-sprachlicher Zeichensysteme; die Beschreibung der Semantik von Emojis in der Emojipedia ist dafür ein Beispiel. Um der Tatsache Rechnung zu tragen, dass man auch nicht-sprachliche Zeichen systemkonform oder systemabweichend verwenden kann, haben wir den Bereich „sprachsystematische Richtigkeit“ des Zürcher Modells um die Teilbereiche „Form nicht-sprachlicher Einheiten“ und „Semantik nicht-sprachlicher Einheiten“ erweitert.
Diese Erweiterung ist auch deshalb sinnvoll, weil die Konventionen für die Bildung netzsprachlicher Einheiten mit sprachlichen Normen in Konflikt geraten können. Die Konvention zur Bildung von Hashtag-Labels erlaubt es beispielweise nicht, mehrere Wortformen durch Leerzeichen zu trennen. Dies führt dazu, dass es oft sinnvoll ist, gegen die Regeln der Getrennt- und Zusammenschreibung zu verstoßen, um aussagekräftige Hashtag-Labels generieren zu können.
Im Internet gibt es viele kommunikative Kontexte und Anlässe, in denen Verstöße gegen orthographische und sprachsystematische Richtigkeit nicht falsch, sondern situativ angemessen und dem Kommunikationsziel zuträglich sind. Um die verschiedenen Facetten der Richtigkeit und Angemessenheit besser unterscheiden zu können, haben wir die feinere Unterscheidung von Bewertungprädikaten übernommen, die in der Arbeit von Thomas Bartz (Bartz 2018) entwickelt und in einem theoretisch fundierten Modell verankert wurden: (1) orthographische Korrektheit, (2) grammatische Wohlgeformtheit, (3) semantische Konsistenz und (4) funktional-thematische Organisation. Bartz (2017, 80) weist darauf hin, dass die normative Verbindlichkeit der Dimensionen von (1) nach (4) abnimmt, sodass Abweichungen von (3) und (4) eigentlich nicht mehr als Fehler, sondern als auffällige Ausprägungen von Unangemessenheit zu bezeichnen sind. Dieses feinere Instrumentarium zur Analyse von Abweichungen bewährt sich auch bei der Analyse von Social-Media-Texten.
Bereich Angemessenheit: Erweiterung für interaktive, multimodale Hypertexte
Im Bereich „Angemessenheit“ haben wir zunächst die drei Teilbereiche des Zürcher Rasters übernommen: funktionale Angemessenheit / Kohärenz, ästhetische Angemessenheit und inhaltliche Relevanz. Im Fokus unserer Arbeiten zur Modernisierung lag der Teilbereich „Verständlichkeit und Kohärenz“, den wir um die Aspekte interaktionaler und multimodaler Kohärenz und den neuen Teilbereich mediale Passung erweitert haben.
Exkurs: Was bedeutet überhaupt „Kohärenz“?
Kohärenz ist ein wichtiges Konzept für die wissenschaftliche Erforschung von Textverstehen und Textverständlichkeit. Vereinfachend gesagt bezeichnet Kohärenz den Sinnzusammenhang, den sich LeserInnen aus einem Text erschließen. Ein verständlicher Text sollte kohärent sein, d.h. so gestaltet, dass LeserInnen den Zusammenhang zwischen den verschiedenen Textbestandteilen rekonstruieren und eine stimmige Interpretation des Textsinns aufbauen können.
AutorInnen können den LeserInnen bei der Kohärenzbildung helfen, indem sie beispielsweise den Zusammenhang zwischen Sätzen durch sprachliche Mittel wie Konnektoren (Verknüpfungswörter) explizit machen. Die Subjunktion „weil“ im Beispielsatz (1) ist eine solche Kohärenzbildungshilfe.
(1) Peter fehlt in der Schule, weil er krank ist.
Die Subjunktion stiftet explizit eine kausale Relation zwischen Haupt- und Nebensatz, d.h. macht klar, dass die im Nebensatz versprachlichte Krankheit der Grund für das im Hauptsatz versprachlichte Fehlen in der Schule ist.
Wichtig für das Verständnis des Kohärenzkonzepts ist allerdings, dass Sinnzusammenhänge nicht notwendigerweise über Kohärenzbildungshilfen an der Textoberfläche angezeigt werden müssen. In vielen Fällen erschließen sich die LeserInnen die Relationen aus ihrem Wissen über die Welt oder aus dem unmittelbaren Kontext. Die beiden Sätze in (2)
(2) Peter fehlt in der Schule. Er ist krank.
würden die meisten LeserInnen in derselben Weise logisch verknüpfen wie das Satzgefüge in (1): Peters Krankheit der Grund für sein Fehlen in der Schule. Dies funktioniert, obwohl der Begründungszusammenhang in (2) nicht explizit versprachlicht ist, sondern von den LeserInnen erschlossen werden muss.
An einem Textbeispiel möchte ich illustrieren, wie viel implizites Wissen in das Verständnis eines Textes einfließen kann:
„Anna war zu Peters Geburtstag eingeladen. Sie fragte sich, ob er schon ein Mühle-Spiel hat. Sie ging in ihr Zimmer und schüttelte ihr Sparschwein, doch es gab keinen Ton von sich.“
Die meisten von uns sind in der Lage, die Sätze dieses Textes als eine in sich stimmige Geschichte zu interpretieren. Viele merken gar nicht, dass man den Zusammenhang zwischen dem ersten und dem zweiten Satz nur erkennen kann, wenn man weiß, dass man zu einer Geburtstagseinladung Geschenke mitbringt und dass ein Mühle-Spiel ein solches Geschenk sein kann. Auch um den Zusammenhang zum dritten Satz verstehen zu können, muss man wissen, dass Geschenke Geld kosten, dass Kinder dieses oft als Münzen in Sparschweinen sammeln und dass Münzen klimpern, wenn man ein Sparschwein schüttelt. All diese Wissensvoraussetzungen stehen nicht im Text; dennoch können LeserInnen die Geschichte gut verstehen, weil sie das erforderliche Weltwissen mitbringen.
Was man an diesem Beispiel zeigen kann: Kohärenz ist keine Kategorie, die man alleine durch die Auswertung von Merkmalen an der Textoberfläche messen kann. Kohärenz entsteht im Zusammenspiel zwischen der Textgestalt und dem Wissen der LeserInnen. Dass Kohärenz keine Eigenschaft der Textoberfläche ist, hat zur Folge, dass sie sich nicht durch Auswertung von Sprachmerkmalen „messen“ lässt. Es ist deshalb auch nicht verwunderlich, dass aktuelle Tools zur automatischen Textqualitätsbewertung hier noch unzulänglich sind, dies hat Leonie Bröcher in ihrer Fallstudie gezeigt.
Dessen ungeachtet ist Kohärenz ein Schlüssel zur Bewertung der Textverständlichkeit und damit ein zentrales Qualitätsmerkmal. Dies gilt insbesondere für Texte, die primär der Wissensvermittlung und -überlieferung dienen. Auch für die öffentliche Diskussion in den sozialen Medien ist Verständlichkeit ein wichtiges Desiderat.
Wir haben im Projekt deshalb die Verständlichkeit und das dahinterstehende wissenschaftliche Konzept der Kohärenz in den Mittelpunkt unserer Arbeiten gestellt.
Multimodale Kohärenz und interaktionale Kohärenz
Das Zürcher Raster ist primär für die Bewertung von Schülertexten gedacht, die schriftlich verfasst und monologisch strukturiert sind. Bilder oder andere multimodale Elemente werden nicht berücksichtigt. Auch Zusammenhänge zwischen Beiträgen verschiedener Interaktionsbeteiligter, also z.B. eine Antwort auf eine Frage oder ein Lob als Reaktion auf einen witzigen Beitrag, spielen keine Rolle.
Für die Analyse von Interaktionen in sozialen Medien reicht dies nicht aus, wie man schon an einem kleinen und einfachen Beispiel demonstrieren kann, das wir der Screenshot-Sammlung von Tschernig und Hertzberg zu ihrer Studie zur altersspezifischen Nutzung von Bildzeichen (Teschernig / Hertzberg 2015) entnommen haben.
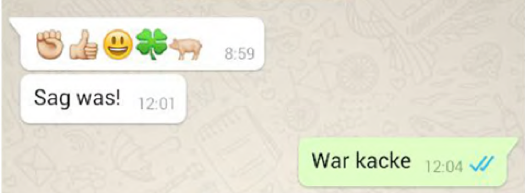
Das Beispiel zeigt einerseits, dass nicht nur mit sprachlichen, sondern auch mit Emojis, also bildlichen Zeichen, kommuniziert wird. Die Interaktion beginnt mit einem um 8.59 Uhr eingetroffenen Beitrag, in dem eine Reihe von Emojis hintereinander gestellt sind, die allesamt aus dem Assoziationsfeld „Glück und Zuversicht“ stammen.
Das Beispiel macht andererseits ein wichtiges Merkmal des interaktionsorientierten Schreibens (Storrer 2018) deutlich: Die beiden Personen kennen sich und können in ihrer Interaktion gemeinsames Vor- und Kontextwissen (einen „common ground“) voraussetzen. Deshalb kann vieles implizit bleiben, was bei einem Text, der auch von Außenstehenden richtig verstanden werden soll, explizit versprachlicht werden müsste. Zwar würden wohl auch die meisten Außenstehenden diesen Ausschnitt als Kommunikation über das Misslingen eines bedeutsamen Ereignisses interpretieren. Der Zeitraum zwischen dem ersten Beitrag mit den Glückwünschen und dem zweiten Beitrag mit der Bitte um Rückmeldung legt nahe, dass es sich bei diesem Ereignis um eine schriftliche Prüfung handelt. Dies sind aber Mutmaßungen – worüber tatsächlich kommuniziert wurde, wissen nur die Beteiligten. Auch ob der derbe Ausdruck „kacke“ in der Situation angemessen ist, können nur die beiden Beteiligten untereinander aushandeln. Dass es sich beim Beitrag „War kacke“ um eine Reaktion auf die Aufforderung „Sag was! handelt, können wir allerdings auch ohne Kontextinformation rekonstruieren. Hierbei helfen uns sprachliche Merkmale – „sag“ als Befehlsform und das Ausrufezeichen am Ende – und unser Wissen über sprachliche Handlungsmuster.
Um diese Kohärenzaspekte, die für die Analyse vieler Texte und Interaktionen im Internet relevant sind, erfassen zu können, haben wir den Bereich „Verständlichkeit / Kohärenz“ um zwei neue Teilbereiche erweitert, nämlich interaktionale Kohärenz und multimodale Kohärenz.
Interaktionale Kohärenz wurde in der Forschung schon früh als nützliche Kategorie für die Analyse internetbasierter Kommunikation identifiziert (Herring 1999). Die Ergänzung des Teilbereichs „interaktionale Kohärenz“ ermöglicht es, semantische Bezüge zwischen Postings einer laufenden Interaktion mit mehreren Beteiligten zu rekonstruieren. Wie wir am Beispiel gezeigt haben, wird hierfür u.a. Wissen über sprachliche Handlungsmuster benötigt, z.B. dass man auf eine Frage eine Antwort erwartet oder auf eine Aufforderung eine passende Reaktion. Die handlungssemantisch fundierte dynamische Texttheorie von Gerd Fritz (Fritz 2013) ist eine sehr gute theoretische Basis für diese Erweiterung.
Mit der Erweiterung um den Teilbereich „multimodale Kohärenz“ tragen wir der Tatsache Rechnung, dass in digitalen Texten und Interaktionsverläufen schriftliche Äußerungen kombiniert sind mit (animierten) Bildern und Graphiken, Audio- und Videodateien aller Art. Die dynamische Texttheorie berücksichtigt solche Erweiterung bereits; der Trierer Medienwissenschaftler Hans-Jürgen Bucher hat diesen Aspekt unter handlungssemantischer Perspektive theoretisch ausgearbeitet (Bucher 2011) und bietet damit eine gute theoretische Basis für die Analyse multimodaler Texte.
Auch die Fallstudien der Bozener Projektgruppe haben gezeigt, dass die Erweiterungen um interaktionale und multimodale Kohärenz notwendig sind. Bei der Untersuchung des Konnektors „weil“ in Facebook-Postings stießen Sie auf neue Verknüpfungsmuster, die sie an folgendem Beispiel illustriert haben:
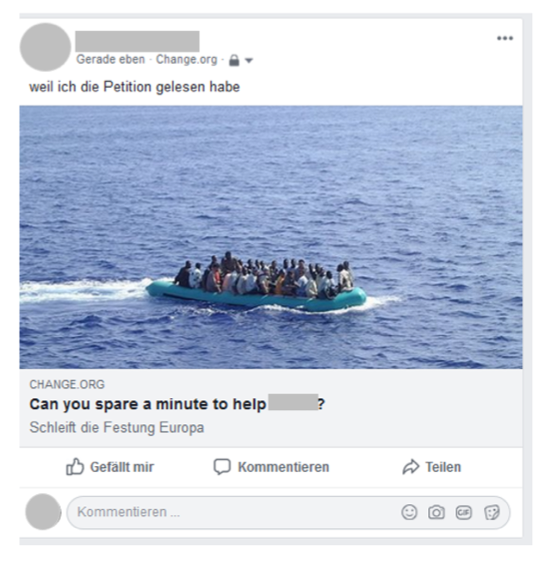
Der schriftliche Teil des Postings ist ein mit „weil“ eingeleiteter Nebensatz „weil ich die Petition gelesen habe“. Dieser ist kombiniert mit einem Bild, das per Link auf eine Seite führt, auf der die Petition unterschrieben werden kann. Um die Konnexion in diesem Beispiel vollständig analysieren zu können, muss man also sowohl interaktive und multimodale Eigenschaften, als auch die Verknüpfung durch Links berücksichtigen (vgl. Abel / Glaznieks i. Dr.).
Links, Hashtags & Co als neue Kohärenzbildungshilfen
Links galten bereits im „klassischen World Wide Web“ als die zentrale Innovation digitaler Hypertexte. Mit den als „Web 2.0“ oder „Social Web“ bezeichneten Veränderungen ist der Umgang mit Links inzwischen so alltäglich geworden, dass viele „digital natives“ heute gar nicht mehr wissen, dass das „h“ hinter „http“ und „HTML“ für „Hypertext“ steht.
Michael Beißwenger und ich haben im Jahr 2002 bereits Ratschläge zum richtigen Umgang mit Hyperlinks zusammengestellt (Wie wird man ein guter Linker?). Sie bezogen sich damals noch auf das „klassische“ Web und müssen für die neuen Typen von Hyperlinks (Hashtags, Adressierungen) und die sozialen Funktionen von Links und Social-Credit-Funktionen (Folgen, Liken etc.) ergänzt werden. Die Analysen der Ratgeberliteratur und auch die Rückmeldungen unserer Praxisexperten im Projekt haben aber ganz eindeutig ergeben, dass der zielgruppenadäquate und verständnisförderliche Umgang mit Vernetzungsmitteln ein zentrales Qualitätsmerkmal für Social-Media-Texte darstellt (Vgl. Blogbeitrag Maja Linthe).
Bei der Modellbildung haben wir deshalb technische Vernetzungsmittel wie Links, Hashtags & Co. als neue Kohärenzbildungshilfen bei der Analyse von Hypertextkohärenz etabliert.
Neuer, vierter Teilbereich „Mediale Passung“
Das Zürcher Textanalyseraster listet die „Erfüllung von Textmusternormen“ als Unterpunkt B1.7. zur Bewertung der funktionalen Angemessenheit. Implizit bezieht sich dieses Kriterium auf Lernertexte, in dem für eine Schreibaufgabe eine Textsorte vorgegeben ist. Für die Bewertung der Textsortenkonformität können dann Vorgaben und Leitlinien zu Aufbau und Sprachmerkmalen herangezogen werden, wie sie im Unterricht vermittelt werden und inzwischen auch im Internet zu finden sind.
Die Bewertung der Textsortenkonformität digitaler Texte ist ungleich schwieriger. Muster zum Aufbau und zum adäquaten Sprachstil bilden sich erst heraus; sie sind ein wichtiger Untersuchungsgegenstand der Internetlinguistik (vgl. Marx / Weidacher 2014). Konventionen für die Angemessenheit des Zeichengebrauchs (incl. neuer Elemente wie Links, Hashtags etc.) bilden sich erst heraus; sie werden in den Communities ausgehandelt und verändern sich immer wieder. Die Kommunikationstechnik beeinflusst den Sprach- und Symbolgebrauch; technische Funktionen verändern sich im Laufe der Zeit (Beispiele hierfür sind die Verdopplung der erlaubten Zeichenzahl in Twitter-Botschaften oder die Einführung von GIFS als neue Ressource in Twitter und WhatApp).
Der Tatsache, dass sich in den sozialen Medien Textmuster und darauf bezogene Norm- und Wertmaßstäbe erst entwickeln, haben wir Rechnung getragen, indem wir die Empfehlungen, Wert- und Qualitätsvorstellungen aus der auf das Web bezogenen Ratgeberliteratur ausgewertet haben. Wir sind dabei auf so viele Aspekte gestoßen, dass wir dies zum Anlass genommen haben, einen neuen Unterbereich zu eröffnen, den wir als „Mediale Passung“ bezeichnen. Wir haben im Bereich „Kategorienfindung“ versucht, die wichtigsten übergreifenden Kategorien für diesen Bereich zu finden und zu systematisieren (vgl. den Blogbeitrag von Maja Linthe).
Natürlich erhebt gerade die Ausarbeitung dieses Bereichs noch keinen Anspruch auf Vollständigkeit. Wir haben mit unserem Modell und dem Analyseleitfaden einen Ansatz entwickelt, der erstmals überhaupt traditionelle Kategorien der Qualitätsbewertung mit Kategorien verbindet, die für soziale Medien relevant sind. Diese übergreifenden Kategorien müssen für die verschiedenen Plattformen und die darin verankerten unterschiedlichen Text- und Kommunikationsformen dann jeweils im Detail untersucht und beschrieben werden. Wir rufen alle dazu auf, daran mitzuarbeiten, weitere Lücken zu füllen oder weiteren Modernisierungsbedarf an Stellen anzumelden, die wir bislang nicht im Fokus hatten.
Wir freuen uns über Kommentare und Anregungen!
